Абсолютно все про новий алгоритм BERT і чим він може вас здивувати

- Що таке BERT: головне про новий пошуковий алгоритм Google
- Технічні подробиці та походження BERT
- Що тепер із RankBrain
- Взаємозв’язок алгоритму BERT із голосовим пошуком
- Вплив алгоритму BERT на пошукові результати
- Приклади алгоритму в дії
- Вплив алгоритму BERT на SEO та ваш сайт
- Як ми можемо підготуватися до майбутнього у нас оновлення BERT
- Більше, ніж просто алгоритм: BERT може завершити ваше речення
У цій статті ми зібрали всю актуальну інформацію про BERT і навіть більше. Як оновлення вплине на SEO, практичні поради з підготовки до нього і чому BERT захоплює не лише SEO-спеціалістів — читайте нижче (усього 12 хвилин).
Що таке BERT: головне про новий пошуковий алгоритм Google
В офіційному оголошенні Google зазначається, що алгоритм BERT (Bidirectional Encoder Representations From Transformers) — це алгоритм глибокого навчання, який базується на технології обробки природної мови (NLP) на основі нейронної мережі. Так, Google вміє збити з пантелику, але насправді все досить просто.
Новий алгоритм покликаний пропонувати користувачам результати, які НАСПРАВДІ відповідають їхньому пошуковому наміру, завдяки своїй здатності розуміти природну мову.
Як саме? BERT навчили (а точніше, він сам навчився, адже належить до алгоритмів машинного навчання) інтерпретувати намір і контекст пошукового запиту, враховуючи всю фразу, а не окремо взяті слова.
Невелике уточнення: BERT наразі розуміє лише англійську і з часом навчиться інших мов. Але фантазувати про роботу BERT українською мовою ми не будемо, тож поки що всі приклади подаємо для англомовних запитів.

Зокрема, йдеться про довгі пошукові запити, сформульовані так, ніби людина їх проговорила. Також BERT правильніше інтерпретує фрази, де є прийменники «for», «to» — вони значно змінюють зміст речення. Приклади будуть далі у статті.
Новий алгоритм навіть може краще розуміти омоніми: «треба почитати батьків» і «треба почитати книгу». Однакове звучання і написання, але абсолютно різний зміст.
Технічні подробиці та походження BERT
Для загального уявлення..
Google давно працював над розумінням мови машинами.
Можна сказати, що BERT почав зароджуватися з 2017 року. Тоді команда Google AI запустила роботу над проєктом Transformers, який передбачав розробку нової структури нейронної мережі для розуміння мови.
Завдяки цій новій структурі слова в пошуковій фразі обробляються у відношенні до інших слів, а не просто слово за словом по порядку.
Так, концепція проєкту Transformers була об’єднана з пошуковим алгоритмом BERT.
Восени 2018 року компанія вперше представила технологію обробки природної мови BERT. Після цього користувачі (самі того не підозрюючи) могли тренувати систему відповідей на свої запитання.
Особливість цього алгоритму полягає саме в його глибокій двонаправленості під час репрезентації контексту фрази. У цій статті Google описано детальний механізм цього процесу.
Новий алгоритм настільки потужний, що кількість ресурсів, необхідних для його роботи, змусила корпорацію повністю розмістити його в хмарі та використовувати Cloud TPU (тензорний процесор). Звичайна апаратура може обмежувати ККД алгоритму.
Що тепер із RankBrain
RankBrain з’явився у 2015 році і був першим методом штучного інтелекту Google для розуміння пошукових запитів. Він аналізує як запити, так і вміст сторінок з індексу Google.
Отже, BERT не замінює RankBrain — це просто додатковий метод для тлумачення контексту фрази, який, найімовірніше, базується на роботі RankBrain.
Тим не менш, це окремі системи, тому під час обробки пошукового запиту (залежно від його складності) можуть застосовуватися як BERT, так і RankBrain. Google визначатиме, за допомогою якого алгоритму краще інтерпретувати пошуковий запит. Не виключається, що для тлумачення пошукового запиту використовуватимуться кілька методів.
Новий алгоритм можна назвати наступним кроком в еволюції розуміння людської мови штучним інтелектом.
Взаємозв’язок алгоритму BERT із голосовим пошуком
Безумовно, голосовий пошук і голосові помічники все більше набирають популярності, тому існує потреба в покращенні їхньої роботи. Адже пошукова система не завжди розуміє, що випливає з контексту сказної фрази.
Останні роки Google впроваджував опції, пов’язані з голосовим пошуком. Тому будь-який поважаючий себе спеціаліст у галузі SEO вже вловив тонкий зв’язок між Voice Search і BERT (ні, не тонкий).
Алгоритм має все необхідне, щоб знайти найбільш релевантний результат для голосового запиту з довгим хвостом. Багато західних спеціалістів переконані, що BERT лише посилить здатність Google точно відповідати на голосові запити і допоможе компанії далеко просунутися в розвитку цієї сфери.
Відтепер варто приділити більше уваги оптимізації під голосовий пошук — ваша можливість отримати додатковий трафік. Про головну особливість оптимізації під голосовий пошук читайте в нашій статті.
Вплив алгоритму BERT на пошукові результати
Оскільки алгоритм поки знає лише англійську, ми можемо лише поділитися досвідом наших західних колег.
- Алгоритм у них працює вже більше тижня, і точно відомо, що він впливає на 1 із 10 пошукових запитів у Google.
- Зміни торкнулися запитів із довгим хвостом і фраз, сформульованих на манер усного мовлення.
- Відзначається, що тепер велику роль відіграють прийменники, які до цього оновлення не мали особливого значення при формуванні семантичного ядра.
- Очікується «зміна гравців» у розділі швидких відповідей Google, оскільки компанія заявила, що алгоритм натренований підбирати найбільш відповідні результати Featured Snippets.
До речі, 99% результатів голосового пошуку з’являються в швидких відповідях, що ще раз говорить про взаємозв’язок BERT із Voice Search.
Приклади алгоритму в дії
Перш ніж запустити BERT, у Google довго його тестували, домагаючись найкращих результатів. Щоб проілюструвати безпосередню роботу алгоритму та його вплив на пошукову видачу, Google підготував такі приклади.
Пошуковий запит: «2019 brazil traveler to usa need a visa».
Результати за запитом «2019 віза для мандрівника з Бразилії до США» до і після оновлення:

Як бачите, до оновлення в результатах пропонувалася стаття для громадян США, які збираються до Бразилії (що абсолютно протилежно наміру запиту), а після оновлення пошуковий результат став релевантним запиту — пропонується сайт консульства США в Бразилії. Таку зміну викликано тим, що алгоритм розуміє прийменники і зміг правильно визначити контекст (звідки і куди подорожує користувач).
Пошуковий запит: «Can you get medicine for someone pharmacy»
Результати за запитом «Чи можеш ти забрати ліки за (замість) когось аптека» до і після оновлення:

Раніше не враховувалося найголовніше слово у цій фразі — «замість» (for), тому в результатах були інструкції з отримання рецепта на ліки. А тепер — відповідь на запитання.
Пошуковий запит: «Parking on a hill with no curb»
Результати за запитом «Стоянка на схилі без бордюру» до і після оновлення:

А ось і приклад із швидкими відповідями. Раніше акцент робився на слові «бордюр» і пропускалося найголовніше — «без» (no). Тепер дізнатися, як припаркуватися на схилі, де немає бордюру, стало набагато легше.
Вплив алгоритму BERT на SEO та ваш сайт
BERT не карає і не винагороджує сайти. Тож видихайте.
Повторюємо ще раз, що змінюється модель розуміння ключових слів алгоритмами пошукової системи. BERT не аналізує контент сторінки.
У Google не сказали, чи варто очікувати більшого чи меншого трафіку, але згадали про нішеві запити. Алгоритм дозволяє пошуковій системі давати точніші відповіді на низькочастотні нішеві запити, тому компанія розраховує, що люди почнуть ними частіше користуватися.
Як ми можемо підготуватися до майбутнього у нас оновлення BERT
Досвід — половина успіху, а він у нас уже є завдяки західним спеціалістам-першопрохідцям.
Потрібно змиритися — неможливо оптимізувати безпосередньо під BERT, але можна (і потрібно) подвоїти роботу зі створення релевантного та якісного контенту.
Google краще розумітиме природну мову і визначатиме зміст та контекст запиту, а отже, він краще визначатиме релевантні цим запитам сторінки. Тому погано написаний, thin контент більше не пройде.
Гаразд, ви впевнені в якості свого контенту. Тепер перевірте, наскільки він придатний для Featured Snippets.

Ні, Google не хоче вас убити (сподіваюся), просто без BERT трохи складно зрозуміти контекст написаного
Ось міні-чек-лист, як потрапити в блоки з відповідями:
- Створюйте контент у розмовній манері, ставте запитання і відповідайте на них.
- Текст краще розміщувати у вигляді коротких, легко читабельних абзаців із підзаголовками.
- Розробляйте інструкції, які стосуються тематики.
- Використовуйте марковані списки, таблиці, розбиття на етапи.
Читаючи між рядків..
Зосереджуємося на створенні контенту, орієнтованого на реальні запитання, які ставить ваша аудиторія. Тому додайте до семантичного ядра сайту ключі з довгим хвостом — ті самі низькочастотники.
Тут виникає закономірне питання — як їх ОРГАНІЧНО впровадити в контент сайту. Зараз, як ніколи, говорять про FAQ (сторінка запитань-відповідей). Цей формат — найкращий вихід із такої ситуації.
Кому треба, ось чек-лист з оптимізації сторінки FAQ.
1) Зберіть релевантні тематиці запитання, що часто задаються. Використовуйте сервіси для збору ключових слів. Ваша мета — питальні запити. Також опитайте менеджерів із роботи з клієнтами, менеджерів із продажу — що найчастіше запитують люди.
Формуйте запитання так, ніби його ставить вам людина, і пишіть максимально читабельну відповідь. Остання вимога більше для пошукового робота, який відповідатиме на голосові запити.
2) Подбайте про зручну навігацію. Якщо запитань багато, створіть зручну логічну структуру часто задаваних запитань. Розбийте запитання на категорії — так легше орієнтуватися і користувачу, і пошуковому роботу (ніж шукати потрібну інформацію у величезному переліку пунктів).
3) Зробіть сторінку FAQ візуально привабливою. Цей пункт для користувачів, адже в сухому тексті ніхто не шукатиме потрібну інформацію. Додайте релевантні до тексту зображення, інфографіку або навіть відео.
4) Розмітьте структуровані дані. Дайте пошуковим роботам зрозуміти, що знаходиться на цій сторінці і для чого. Є шанс, що FAQ потрапить у пошукову видачу. І тоді плюс до привабливості сторінки в пошуку, плюс до CTR і мінус конкуренти в ніші (їхні позиції будуть нижче). Для цього використовуйте розмітку FAQPage у форматі JSON-LD.
Більше, ніж просто алгоритм: BERT може завершити ваше речення
Google зазначає, що BERT знаменує собою новий етап у пошуку, оскільки це один із найвизначніших кроків, які компанія зробила за всю свою історію.
Ми розглядаємо цей алгоритм як новий етап у розумінні машинами людей, і, чесно кажучи, BERT просто вражає.
У серпні дослідники з Інституту штучного інтелекту Аллена провели тест для ШІ англійською мовою. Їхнім завданням було продовжити речення, вибравши відповідь із кількох варіантів. Наприклад, таке завдання:
Жінка сідає за рояль на сцені. Вона…
1) сидить на стільці, поки її сестра грається з лялькою;
2) з кимось сміється, поки грає музика;
3) перебуває в натовпі, спостерігаючи за танцюристами;
4) нервово кладе пальці на клавіші.
Усім нам відповідь очевидна, але роботам було складніше — вони справлялися приблизно з 60% тестових питань. Для порівняння — люди проходили тест у середньому на 88%.
Коли Google анонсував свій алгоритм BERT, він також пройшов цей тест. BERT впорався так само, як і людина. Увага (!), він навіть не був створений для проходження цього тесту.
А тепер уявіть.
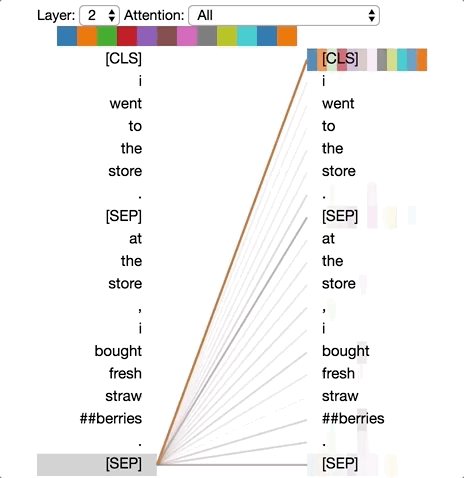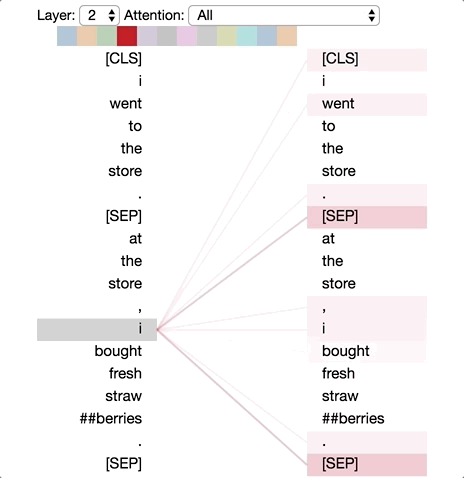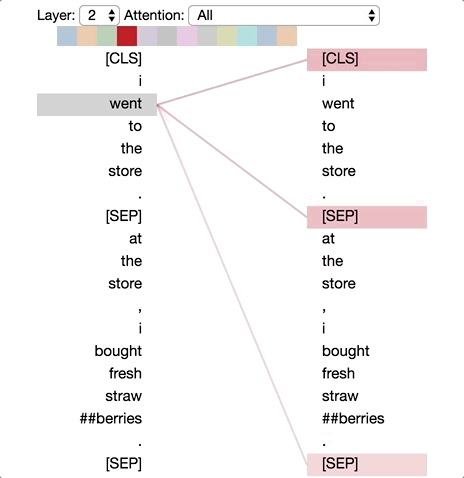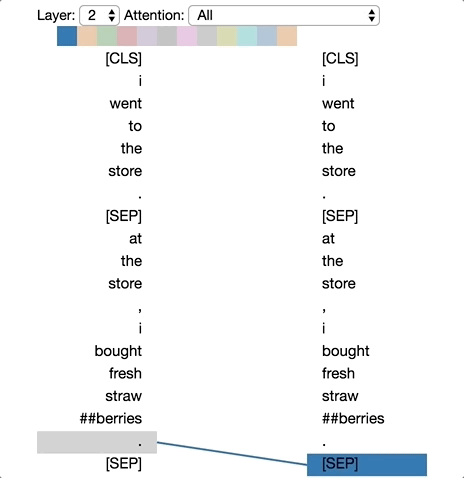
BERT за кілька днів проаналізував безліч статей із Вікіпедії, навчився і почав застосовувати ці знання. Він навчився вгадувати пропущені слова в будь-якому місці будь-якого речення. Наприклад, «Я зайшов у магазин і купив _____ молока».
Дослідники запропонували BERT проаналізувати безліч питань і відповідей на них. Незабаром алгоритм умів самостійно давати відповіді вже на зовсім інші незнайомі запитання.
Вчені показували алгоритму різні новинні заголовки однієї й тієї ж події. BERT навчився розпізнавати два схожі речення, якщо в них закладено однаковий зміст (ні, ось так — ЗМІСТ). Зазвичай штучний інтелект розпізнає схожі речення, якщо в них є точні відповідності.
BERT може похвалитися тестом на розуміння прочитаного. Він обробляв статтю з енциклопедії, а потім відповідав на запитання типу «Що таке кисень?», «Що таке опади?».
І ось супернавичка, на мою думку: BERT може визначити, хороший фільм чи поганий, аналізуючи відгуки про нього.
BERT досяг успіху, тому що для його роботи використовуються великі обчислювальні потужності, яких раніше не було.
На завершення..
BERT поки що темна конячка, і ми продовжуємо стежити за оновленням інформації про нього. А поки переглядаємо семантичне ядро :)







