Як створити правильний Robots.txt
Ні для кого не секрет, що успішне просування інтернет-ресурсу в пошукових системах повністю залежить від безлічі факторів. Зараз напевно всі подумали про кількість якісних зовнішніх посилань прийнятих сайтом, що просувається? На жаль, цей фактор з кожним днем все менше впливає на ранжування.
Комплексний підхід завжди кращий і економніший за зовнішні посилання!
Не приховуватиму, що більшість SEO-компаній і фрілансерів досі активно користуються біржами посилань, і досягають певних успіхів, але сьогодні позитивний результат у просуванні максимально залежить від коректної внутрішньої оптимізації, до якої можна віднести:
- розробку сайту на якісній CMS-системі;
- грамотну структуру сайту;
- коректне налаштування файлів, які є інструкціями для пошукових роботів;
- відсутність дублюючого контенту;
- і багато іншого, адже повний список не знає ніхто крім самої пошукової системи.
Для того, щоб ресурс був максимально коректно розроблений і готовий до просування, на початковому етапі створення рекомендується залучити SEO-фахівця, який зміг би вберегти надалі від багатьох доробок та недоліків.
У моїй практиці зустрічалася велика кількість сайтів, розроблених різними «умільцями», після яких ресурс просто неможливо просувати в пошукових системах без впровадження цілого списку дорогих програмних та SEO-доробок. Але існують й інші сайти, створені на основі популярних CMS-систем, наприклад таких як Joomla або WebAsyst – не ідеальні, але їх просування реально втілити в життя за допомогою якісного налаштування інструкцій для роботів та оптимізації контентної частини.
Так давайте і розберемо це якісне налаштування інструкцій, головним пунктом якої є складання правильно файлу robots.txt.
Покрокова інструкція щодо створення Robots.txt
![]()
Для початку давайте розберемося, що таке файл robots.txt, для чого він потрібен і де повинен бути розташований. Отже robots.txt – файл, зазвичай розташований у кореневій папці сайту формату TXT з набором правил для пошукових роботів, які служать як виконувана інструкція під час індексації сайту.
Щоб зрозуміти які правила в ньому повинні бути і які бути відсутніми, необхідно розібратися в тому, як пошукові боти можуть переміщатися по сторінках та посиланнях (внутрішнім та зовнішнім), скануючи ваш сайт.
Багато SEO-фахівці користуються вже готовими підказками від пошукових систем, а саме переглядають усі проіндексовані сторінки в пошуковій видачі, тим самим вибираючи неякісні або ті, які необхідно заборонити індексувати на їхню суб'єктивну думку. Це вірний спосіб, але він не завжди може бути правильним, оскільки не всі сторінки можуть перебувати в індексі тієї чи іншої пошукової системи, яку необхідно закрити.
Як же бути в цьому випадку? Все гранично просто: існує безліч програм та сервісів, наприклад програма Screaming Frog SeoSpider, XEnu або сервіс
mysitemapgenerator.com, за допомогою яких можна спарсити абсолютно всі існуючі URL-адреси сайту без урахування поточного robots.txt (у разі, якщо він присутній), після чого з цього списку всі знайдені URL:
сторінки, які мають індексувати бот;
дублі та службові сторінки, які необхідно заборонити індексувати.
З першого списку url-адрес надалі формується карта сайту XML, по другому складаються інструкції, що забороняють індексування цих сторінок.
Наприклад:

Сторінки, що потрапили до другого списку, не несуть корисної інформації для користувачів і є службовими, їх необхідно закрити у файлі robots.txt. Для цього необхідно скористатися такими правилами:
1. Для закриття сторінки /login/ використовуємо
Disallow: /login/
2. Для закриття другої, можна використовувати кілька правил, наприклад закрити її за цілою url-адресою або за маскою (частина повторюваної адреси), якщо в повному списку присутні й інші схожі сторінки, які необхідно також закрити.
Disallow: *route=
Таким чином, необхідно перебрати всі сторінки сайту, закривши непотрібні, після чого рекомендується перевірити файл robots.txt в панелі веб-майстрів Яндекс.
Спочатку перевіряємо потрібні нам сторінки:
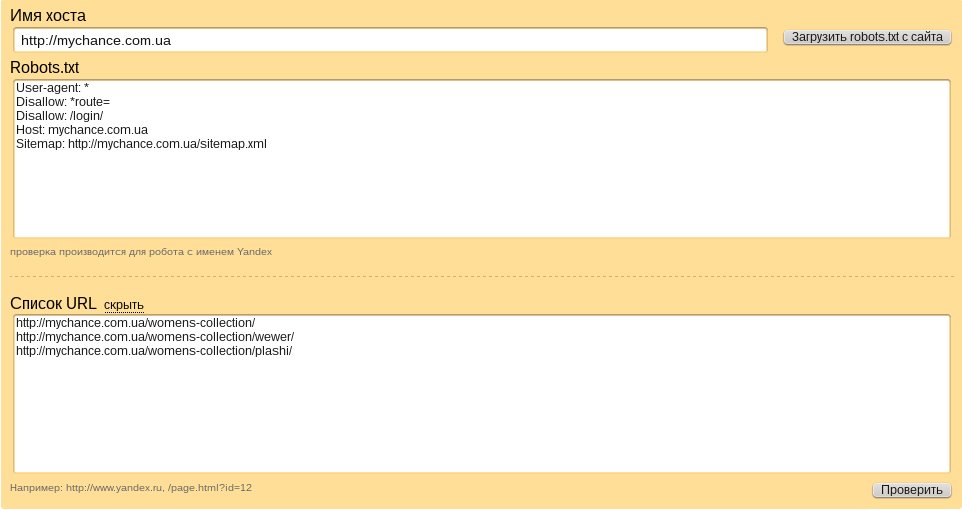
це необхідно зробити для того, щоб переконатися в правильності складеного файлу.

Після того, як ми переконалися в тому, що всі потрібні нам сторінки доступні пошуковому боту, необхідно перевірити той список, який ми хочемо приховати від індексування, попередньо додавши всі URL для сміття адреси у відповідне поле:
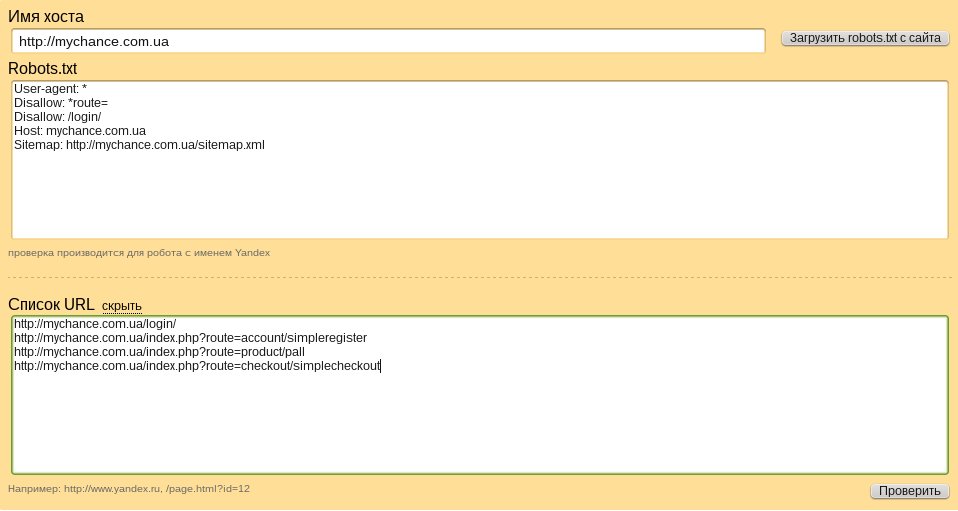
це необхідно виконати для того, щоб бути впевненим, що пошуковий робот не буде індексувати сторінки з другого списку.

У нашому випадку файл сформований коректно та готовий для розміщення у кореневій папці сайту.
Ну і нарешті, якщо ви хочете спасти спокійно поки пошукові боти подорожують вашим сайтом, після додавання проробленого файлу в корінь сайту рекомендується спарсити ще раз усі сторінки програмою або сервісом, перерахованими вище, тільки вже з урахуванням існуючого robots.txt. Якщо у списку, що сформувався, не було знайдено жодної сторінки, яку необхідно закрити, значить ваш robots.txt ідеально оптимізований. Залишається тільки залити коректну xml-карту на FTP та повідомити пошукові системи про список корисних URL-адрес у веб-местері Google.






